Explorative Data Analysis¶
Explorative Data Analysis (EDA) is a technique based on the human characteristic of visual pattern recognition.
The purpose of EDA is simple: learn more about data by visualizing it in different ways.
“Experts often possess more data than judgment.” - Colin Powell
“Exploratory data analysis is graphical detective work.” - John W. Tukey, considered the founder of EDA
Get Overview of Data¶
A first step is getting an overview of the whole data set and specific series of it.
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/retomarek/edap/main/edap/sampleData/flatTempHum.csv",
sep = ";")
df
| time | FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-10-03 00:00:00 | 53.0 | 24.43 | 38.8 | 22.40 | 44.0 | 24.5 | 49.0 | 24.43 |
| 1 | 2018-10-03 01:00:00 | 53.0 | 24.40 | 38.8 | 22.40 | 44.0 | 24.5 | 49.0 | 24.40 |
| 2 | 2018-10-03 02:00:00 | 53.0 | 24.40 | 39.3 | 22.40 | 44.7 | 24.5 | 48.3 | 24.38 |
| 3 | 2018-10-03 03:00:00 | 53.0 | 24.40 | 40.3 | 22.40 | 45.0 | 24.5 | 48.0 | 24.33 |
| 4 | 2018-10-03 04:00:00 | 53.3 | 24.40 | 41.0 | 22.37 | 45.2 | 24.5 | 47.7 | 24.30 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 17176 | 2020-09-17 16:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 17177 | 2020-09-17 17:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 17178 | 2020-09-17 18:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 17179 | 2020-09-17 19:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 17180 | 2020-09-17 20:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
17181 rows × 9 columns
df.head(3)
| time | FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-10-03 00:00:00 | 53.0 | 24.43 | 38.8 | 22.4 | 44.0 | 24.5 | 49.0 | 24.43 |
| 1 | 2018-10-03 01:00:00 | 53.0 | 24.40 | 38.8 | 22.4 | 44.0 | 24.5 | 49.0 | 24.40 |
| 2 | 2018-10-03 02:00:00 | 53.0 | 24.40 | 39.3 | 22.4 | 44.7 | 24.5 | 48.3 | 24.38 |
df.tail(2)
| time | FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|---|
| 17179 | 2020-09-17 19:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 17180 | 2020-09-17 20:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
df.shape
(17181, 9)
df.dtypes
time object
FlatA_Hum float64
FlatA_Temp float64
FlatB_Hum float64
FlatB_Temp float64
FlatC_Hum float64
FlatC_Temp float64
FlatD_Hum float64
FlatD_Temp float64
dtype: object
Note
The type “object” normally points to unclean data, e.g. the time which should be a datetime object
Descriptive Statistics¶
df.describe()
| FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|
| count | 16484.000000 | 16484.000000 | 16470.000000 | 16470.000000 | 16497.000000 | 16497.000000 | 16354.000000 | 16354.000000 |
| mean | 54.336599 | 23.786531 | 49.666697 | 23.404749 | 48.895339 | 23.964698 | 49.299156 | 24.134841 |
| std | 6.300389 | 1.273444 | 6.903822 | 1.470354 | 6.487768 | 1.360014 | 6.524641 | 1.308097 |
| min | 23.500000 | 19.100000 | 25.000000 | 20.530000 | 22.500000 | 21.380000 | 20.500000 | 18.120000 |
| 25% | 51.000000 | 22.800000 | 44.700000 | 22.320000 | 44.300000 | 22.880000 | 44.300000 | 23.030000 |
| 50% | 54.800000 | 23.480000 | 50.000000 | 23.000000 | 49.200000 | 23.600000 | 49.000000 | 23.700000 |
| 75% | 58.300000 | 24.600000 | 54.500000 | 24.100000 | 53.800000 | 24.800000 | 54.000000 | 25.200000 |
| max | 76.500000 | 28.880000 | 73.300000 | 29.120000 | 69.800000 | 28.800000 | 69.800000 | 28.030000 |
df.describe(include="all")
| time | FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|---|
| count | 17181 | 16484.000000 | 16484.000000 | 16470.000000 | 16470.000000 | 16497.000000 | 16497.000000 | 16354.000000 | 16354.000000 |
| unique | 17181 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| top | 2020-03-04 09:00:00 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| freq | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| mean | NaN | 54.336599 | 23.786531 | 49.666697 | 23.404749 | 48.895339 | 23.964698 | 49.299156 | 24.134841 |
| std | NaN | 6.300389 | 1.273444 | 6.903822 | 1.470354 | 6.487768 | 1.360014 | 6.524641 | 1.308097 |
| min | NaN | 23.500000 | 19.100000 | 25.000000 | 20.530000 | 22.500000 | 21.380000 | 20.500000 | 18.120000 |
| 25% | NaN | 51.000000 | 22.800000 | 44.700000 | 22.320000 | 44.300000 | 22.880000 | 44.300000 | 23.030000 |
| 50% | NaN | 54.800000 | 23.480000 | 50.000000 | 23.000000 | 49.200000 | 23.600000 | 49.000000 | 23.700000 |
| 75% | NaN | 58.300000 | 24.600000 | 54.500000 | 24.100000 | 53.800000 | 24.800000 | 54.000000 | 25.200000 |
| max | NaN | 76.500000 | 28.880000 | 73.300000 | 29.120000 | 69.800000 | 28.800000 | 69.800000 | 28.030000 |
df["FlatA_Temp"].min()
19.1
df["FlatA_Temp"].max()
28.88
df["FlatA_Temp"].median()
23.48
df["FlatA_Temp"].mean()
23.786531181752004
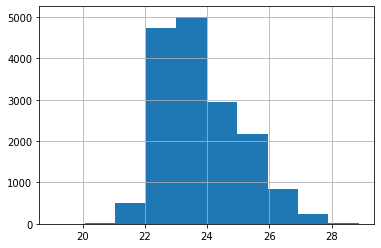
Histograms¶
df["FlatA_Temp"].hist()
<AxesSubplot:>