Time Series¶
# Load data set
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/retomarek/edap/main/edap/sampleData/flatTempHum.csv",
sep = ";")
df['time'] = pd.to_datetime(df['time'], format='%Y-%m-%d %H:%M:%S')
df.head()
| time | FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-10-03 00:00:00 | 53.0 | 24.43 | 38.8 | 22.40 | 44.0 | 24.5 | 49.0 | 24.43 |
| 1 | 2018-10-03 01:00:00 | 53.0 | 24.40 | 38.8 | 22.40 | 44.0 | 24.5 | 49.0 | 24.40 |
| 2 | 2018-10-03 02:00:00 | 53.0 | 24.40 | 39.3 | 22.40 | 44.7 | 24.5 | 48.3 | 24.38 |
| 3 | 2018-10-03 03:00:00 | 53.0 | 24.40 | 40.3 | 22.40 | 45.0 | 24.5 | 48.0 | 24.33 |
| 4 | 2018-10-03 04:00:00 | 53.3 | 24.40 | 41.0 | 22.37 | 45.2 | 24.5 | 47.7 | 24.30 |
Datetime index¶
# set index and remove column
df = df.set_index("time", drop=True)
# remove duplicates
df = df[~df.index.duplicated(keep='first')]
df.head()
| FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|
| time | ||||||||
| 2018-10-03 00:00:00 | 53.0 | 24.43 | 38.8 | 22.40 | 44.0 | 24.5 | 49.0 | 24.43 |
| 2018-10-03 01:00:00 | 53.0 | 24.40 | 38.8 | 22.40 | 44.0 | 24.5 | 49.0 | 24.40 |
| 2018-10-03 02:00:00 | 53.0 | 24.40 | 39.3 | 22.40 | 44.7 | 24.5 | 48.3 | 24.38 |
| 2018-10-03 03:00:00 | 53.0 | 24.40 | 40.3 | 22.40 | 45.0 | 24.5 | 48.0 | 24.33 |
| 2018-10-03 04:00:00 | 53.3 | 24.40 | 41.0 | 22.37 | 45.2 | 24.5 | 47.7 | 24.30 |
Note
The index column with 0, 1, 2 etc. has gone and now datetime is the index!
Upsampling¶
Increase the frequency of the samples, such as from hours to 15min
df15min = df.resample("15min").interpolate(method="linear")
df15min.head()
| FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|
| time | ||||||||
| 2018-10-03 00:00:00 | 53.0 | 24.4300 | 38.8 | 22.4 | 44.0 | 24.5 | 49.0 | 24.4300 |
| 2018-10-03 00:15:00 | 53.0 | 24.4225 | 38.8 | 22.4 | 44.0 | 24.5 | 49.0 | 24.4225 |
| 2018-10-03 00:30:00 | 53.0 | 24.4150 | 38.8 | 22.4 | 44.0 | 24.5 | 49.0 | 24.4150 |
| 2018-10-03 00:45:00 | 53.0 | 24.4075 | 38.8 | 22.4 | 44.0 | 24.5 | 49.0 | 24.4075 |
| 2018-10-03 01:00:00 | 53.0 | 24.4000 | 38.8 | 22.4 | 44.0 | 24.5 | 49.0 | 24.4000 |
Note
Other upsample methods are
.interpolate(method=”linear”)
.interpolate(method=”spline”, order=2) # gives more natural curve like data
.bfill()[:15] # backwards fill
.pad()[:15] # forwards fill
Note
Other Frequencies
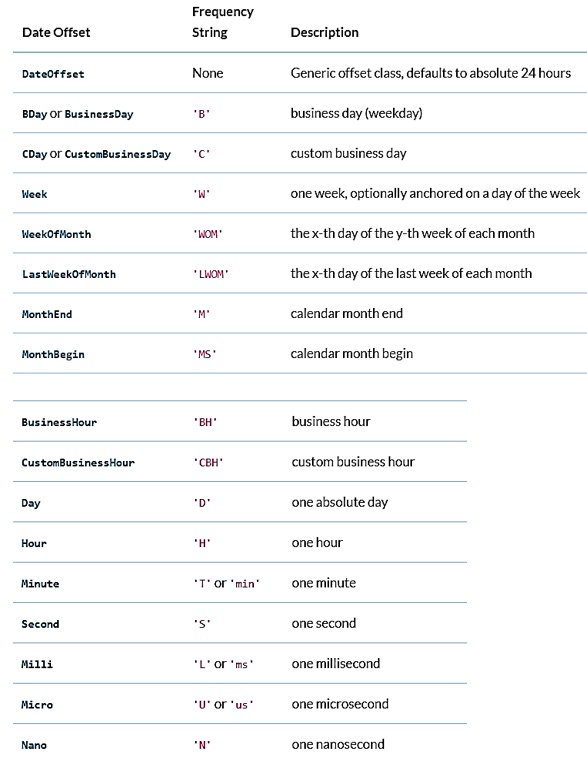
Downsampling¶
Decrease the frequency of the samples, such as from hours to days
dfDaily = df.resample("D").mean()
dfDaily.head()
| FlatA_Hum | FlatA_Temp | FlatB_Hum | FlatB_Temp | FlatC_Hum | FlatC_Temp | FlatD_Hum | FlatD_Temp | |
|---|---|---|---|---|---|---|---|---|
| time | ||||||||
| 2018-10-03 | 50.547826 | 24.200435 | 43.379167 | 22.627917 | 46.070833 | 24.632500 | 50.652381 | 24.458571 |
| 2018-10-04 | 54.033333 | 24.232083 | 47.366667 | 22.797500 | 47.812500 | 24.655417 | 48.078261 | 24.489565 |
| 2018-10-05 | 52.682609 | 24.210435 | 47.858333 | 23.095417 | 47.962500 | 24.747500 | 50.533333 | 24.621250 |
| 2018-10-06 | 52.708696 | 24.180435 | 49.645833 | 23.322500 | 51.183333 | 24.600000 | 52.054167 | 24.573750 |
| 2018-10-07 | 56.058333 | 24.296667 | 51.662500 | 23.587083 | 53.541667 | 24.565417 | 50.973913 | 24.384783 |
Note
Other downsample methods are
.min()
.max()
.median()
.mean()
.sum()
etc.